Zápočtové programy z jazyka C
Zápočtové programy
Programy existují ve variantě Základ, ve variantě Náročnější a ve variantě Express. Každý, kdo má ke dni zadání dvě a méně absencí, přičemž každé dva neodevzdané domácí úkoly (symbol w v docházce) se počítají jako jedna absence (jeden symbol za půlku), dělá základní variantu. Všichni ostatní musí udělat náročnější zápočtový program. Zápočtový program Express je určen pro ty studenty, kteří již mají zkušenosti s jazykem C a chtějí získat zápočet ihned bez docházky. Pokud se student rozhodne dělat zápočtový program Express, musí ho dokončit v řádném termínu, jinak nebude zápočet udělen. Dále není možné program rozdělat a následně přehodnotit a začít opět s docházkou (rozhodnutí je závazné a nevratné).
Program musí být napsaný v jazyce C (včetně C11), musí při odevzdání fungovat, musí jít přeložit a musí mít bezchybnou práci s pamětí – nástroj Valgrind nesmí najít únik paměti (velmi důležité, nicméně externí knihovny mohou produkovat chybová hlášení). Narazíte-li na komplikaci či chybu v zadání, neváhejte se na mě obrátit prostřednictvím mailu. Nekonzultujte, prosím, programy mezi sebou. Při opisování nebude zápočet udělen.
Úpravy zadání
- 22.10.2013, express – Změna stylu předávání souboru s databází do programu. Má se použít parametr příkazové řádky a ne standardní vstup.
Základ – Kódy pro začátečníky
Jako každý rok se těšíte, jak s kamarády v týmu vyrazíte do noční Prahy prožít Bednu. Abyste se ale vůbec dostali ze startu, bude dobré procvičit si sadu základních kódů, mezi které patří i Morseova abeceda. Jelikož v týmu umíte nejlépe programovat, navrhnete ostatním, že připravíte tréninkový program, který bude překládat text do Morseovky.
Vytvořte program, který obdrží definiční soubor s kódem Morseovy abecedy, a který bude umět převést čistý text do Morseovky a zpět. Program bude umět pracovat i s neúplnou definicí kódu a výsledek bude ukládat do souboru.
K implementaci
Program bude očekávat jméno vstupního definičního souboru jako parametr příkazové řádky. Pokud parametr nebude uveden, bude program očekávat soubor morse.def. Definiční soubor bude mít následující strukturu.
A .-
B -...
C -.-.
D -..
. .-.-.-.
, --..--
? ..--..Každá řádka bude obsahovat kód jednoho znaku. Nejprve bude uveden znak (tisknutelný z tabulky ASCII), pak libovolný počet mezer a následovat bude sada znaků tečka a pomlčka tvořící kód Morseovky. Ne všechny znaky anglické abecedy musejí být uvedeny, některé v definičním souboru mohou chybět. Není potřeba ověřovat unikátnost Morseovkového kódu, budeme předpokládat, že každý znak má jedinečný kód. Délka kódu nikdy nepřesáhne 16 znaků.
Poté, co program načte převodní tabulku z definičního souboru, bude očekávat v parametru příkazové řádky pokyn encode nebo decode, který bude určovat směr kódování do Morseovky, resp. z Morseovky. Pokud parametr nebude uveden, bude program provádět kódování do Morseovy abecedy.
Jádrem programu budou dva binární nevyvážené stromy. Jeden bude sloužit pro převod znaků do kódové abecedy, ten druhý bude pro opačný převod. V kódovacím stromu budou klíčem znaky ASCII (písmena uvažujte pouze velká) a hodnotami budou kódy Morseovy abecedy. Naproti tomu v druhém, dekódovacím stromu, budou klíčem řetězce z teček a čárek (implicitně uložené v cestách ve stromu) a hodnotou bude znak ASCII (vizte obrázek níže).
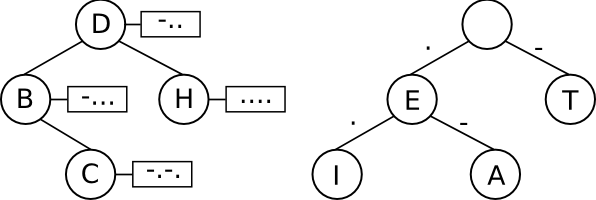
Kódovací a dekódovací strom Morseovy abecedy.
Program bude očekávat vstup pro kódování nebo dekódování na standardním vstupu. Při kódování se vždy přečte jeden znak, převede se na velká písmena, vyhledá se v kódovacím stromu, a v případě, že je nalezen správný kód, se výstup zapíše do výstupního souboru s názvem encoded.txt. Když znak nebude nalezen, vypíše se na standardní chybový výstup text
error: cannot encode character 'X'a program bude pokračovat v kódování dalších znaků. Nezapomeňte, že mezera se v Morseovce kóduje jako dvě lomítka. Pokud bude ve zdrojovém textu více mezer za sebou, kódujte vždy jen jednu. Písmena Morseovky se oddělují jedním lomítkem.
Při zpětném dekódování bude nutné načíst řetězec reprezentující jedno písmeno (oddělený jedním lomítkem od zbytku) a poté projít postupně dekódovací strom tak, že tečka způsobí posun doleva, čárka doprava. Pokud se podaří nalézt znak příslušející sekvenci Morseovy abecedy, vypíše se znak do výstupního souboru decoded.txt. Když znak nebude nalezen, vypíše se na standardní chybový výstup text
error: cannot decode sequence '.----'a program bude pokračovat v dekódování dalších znaků. Dvojitá lomítka převádějte zpět na mezery.
Náročnější – Čtení, psaní, počítání
Úroveň dnešních školáků je bídná, a proto nastupuje naše firma Vědátor, s.r.o. s řešením situace. Největší propad českých školáků je v matematice. Již ve starých časech existovala účinná metoda výuky – dril, dril, dril. Jelikož si však doba žádá moderní přístup, rozhodli jsme se připravit pro studenty učební pomůcku.
Učitel připraví textový soubor s příklady z počtů. Jelikož cílíme na žáky základních škol, kde je jádro problému, budeme podporovat jen sčítání a odčítání. V textovém souboru budou příklady zapsané v klasické matematické notaci, vždy jeden příklad na řádek. Délka řádku může být libovolná. Následuje ukázka souboru s příklady:
3
2+3
-1 +(2.1 + 3.5)
(((((((1 + 1.0) + 1) +1) + 1)+ 1) + 1) + 1)
-(3 + 4) + (-1 - 2)
((3-1.12345)
()
1.23E2
Program bude očekávat vstupní soubor s názvem vstup.txt v adresáři programu. Po spuštění se pokusí nalézt soubor, a pokud ho nenalezne, nahlásí "soubor vstup.txt nenalezen" a skončí. Je-li soubor nalezen, bude se program ptát na jednotlivé výsledky uživatele otázkou "Vysledek dane ulohy <uloha> je?". Pokud uživatel odpoví správně, bude pochválen "Vyborne, jen tak dal", pokud student odpoví špatně, bude pokárán "Snaz se vic, i opice pocita lepe!". Je-li příklad špatně zadán, jako je tomu v případě posledních tří řádek ukázky, vypíše program "I mistr tesar se nekdy utne:." následovaná popiem chyby (např. Neukoncena zavorka, Neocekavany symbol, atd.) a daná úloha se přeskočí. Na konci student obdrží výsledné skóre ve formě "Dobre vyresenych prikladu: 2 z 5 a 1 chybne zadan" (skloňování neřešte).
K implementaci
V tomto programu je zakázáno používat funkci sscanf() , fscanf(), strtol() a strtod(). Program musí nejprve vypočítat výsledek každého příkladu. K tomu se využije binární strom, v němž se vymodeluje celý příklad (viz obrázek) a následně se strom projde. Uvažujeme pouze celá dekadická čísla a necelá čísla s desetinnou tečkou (tedy bez zápisu s exponentem) a pouze operace sčítání a odčítání. Závorky se mohou vyskytovat libovolně, musí ale být vždy řádně uzavřené. Uvažujeme pouze kulaté závorky. Prázdné závorky, přestože budou správně uzavřené, nejsou povoleny.
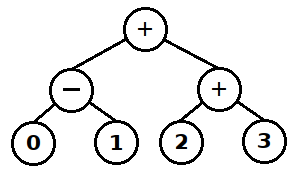
Strom výrazu -1 + (2 + 3)
Strom je potřeba poskládat rekurzivně při průchodu řetězce. Každý operátor bude reprezentován stromem o třech uzlech. Ve vrcholu stromu bude operátor, v listech stromu bude levý a pravý operand. Půjde-li o unární operátor, bude v levém listu vytvořen nulový uzel (vizte obrázek výše). Pokaždé, když se narazí na závorku, bude nutné rekurzivně vyskládat strom výrazu v závorce a ten pak připojit do výsledného stromu buď jako levý, nebo jako pravý operand příslušného operátoru. Výsledkem bude vždy strom, který bude mít ve vnitřních uzlech operátory a v listech čísla.
Express – Pomozte VIC
VIC je v koncích! Počet uživatelů dosáhl kritické úrovně a doba pro ověření jedné karty v systému se stala neúnosná. Vy, jako nejlepší vývojáři, máte tuto ostudnou situaci změnit tím, že přepíšete systém ověřování uživatelů tak, aby byl co nejrychlejší. Rozhodli jste se proto napsat demo aplikaci, na které si vyzkoušíte zamýšlené postupy.
Vytvořte aplikaci, která načte databázi uživatelů, ve které pak půjde vyhledávat podle přihlašovacího jména nebo ID uživatele. Program bude data uchovávat v indexované databázi.
K implementaci
Program obdrží jako parametr příkazové řádky název souboru s databází uživatelů ve formátu XML. Jeho ukázku vidíte v následujícím výpisu. Uživatelská data budou zahrnovat křestní jméno a příjmení a také unikátní ID číslo karty uživatele. Na délku jména není kladeno žádné omezení, délka ID čísla by vždy měla mít 10 číslic (ověřte). Záznamy pro jednoho uživatele jsou vždy uzavřeny do elementu user. Všechny elementy user jsou obalené kořenovým elementem users. Pořadí záznamů může být libovolné, ale zanoření elementů je pevné a jakékoliv prohřešky by měly být hlášeny.
Syntaxe vstupního souboru je následující.
<?xml version="1.0"?>
<users>
<user>
<firstname>Marek</firstname>
<lastname>Testovic</lastname>
<id>0123456789</id>
</user>
<user>
<id>0123786789</id>
<firstname>Bob</firstname>
<lastname>Hu</lastname>
</user>
<user>
<lastname>Adela</lastname>
<firstname>Novakova</firstname>
<id>0123456789</id>
</user>
<!-- více uživatelů může následovat -->
</users>Pro načítání XML souboru využijte knihovnu libxml2, která je dostupná na více platformách. Použijte Reader API z dané knihovny. Tato knihovna může mást Valgrind, který pak bude hlásit neuvolněnou dostupnou paměť.
Kromě výše uvedených údajů bude pro každého uživatele vygenerováno jeho přihlašovací jméno, které bude mít následující strukturu. Prvních šest znaků bude tvořeno malými písmeny příjmení a křestního jména, vždy nejprve tři znaky příjmení a poté tři znaky jména. Pokud je jméno kratší, bude zbytek doplněn písmenem x. Pokud je takové uživatelské jméno unikátní, bude takto uložené v databázi. V případě konfliktu bude nutné za prvních šest znaků přidat pořadové číslo začínající jedničkou (pro druhého uživatele se stejným jménem). Jelikož se neočekává více než sto uživatelů se stejným jménem, bude číslo omezeno na maximálně dvě číslice. Následuje příklad.
1. Marek Testovic -> tesmar
2. Marek Testo -> tesmar1
3. Martin Tesanek -> tesmar2
..
11. Marek Testovic -> tesmar10
1. Bob Hu -> huxbobV případě, že dva uživatelé budou mít stejná ID čísla, odmítne program přidat druhého z nich a vypíše na chybový výstup:
cannot add user Tomas Testovic to database: id already existsVšechna data načtená za vstupního souboru bude nutné uložit do databáze, která bude tvořena spojovým seznamem záznamů. Avšak pozor, lineární průchod je nepřípustný z důvodu velké složitosti, a proto bude nutné zavést indexování. Indexována budou ID čísla a přihlašovací jména. Indexování bude provedeno pomocí binárního vyvažovaného AVL stromu (vizte obrázek níže). Implementace AVL stromu bude obecná, půjde tedy o strukturu s obecným klíčem udržující obecná data. Každá instance AVL stromu obdrží ve své inicializační funkci komparační funkci, která bude sloužit pro porovnávání klíčů (podobně jako ve funkci qsort()). AVL strom musí obsahovat alespoň tyto funkce.
int initializeTree (AVLTree *tree, int (*compare)(const void *, const void *));
int insertItem (AVLTree *tree, void *index, void *data);
void* searchTree (AVLTree *tree, const void *index);
int removeItem (AVLTree *tree, void *index);
void destroyTree (AVLTree *tree);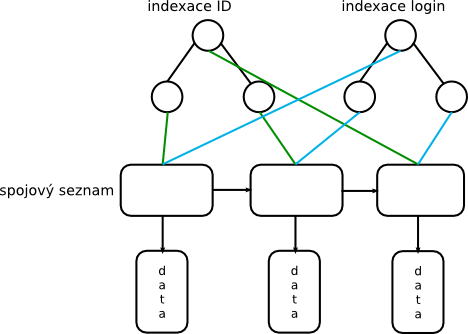
Schéma indexované databáze.
Databáze bude využívat konkrétní podobu AVL stromů s klíčem typu const char* a daty typu ukazatel na buňku seznamu. Jeden strom bude sloužit pro vyhledávání podle ID, druhý podle přihlašovacího jména. V případě mazání uživatele bude nutné odmazat data ze spojového seznamu a také záznamy v obou stromech.
Po úspěšném načtení vstupu program zobrazí interaktivní menu, ve kterém si bude možné vybrat následující úkony.
1. add user to database
2. search user by ID
3. search user by login
4. delete user by ID
5. delete user by login
6. finish
Select action:Do databáze bude možné přidat nového uživatele se jménem, příjmením a ID číslem. V případě konfliktu v ID číslu program záznam nepřidá. Půjde vyhledávat podle ID nebo uživatelského jména. Výstup z vyhledávání bude vypadat následovně:
user found
first name: Marek
last name: Testovic
login: tesmar
ID number: 0123456789Když uživatel nebude existovat, vypíše program
user not foundUživatele půjde dále mazat podle ID a uživatelského jména.
Následuje bodový soupis úkonů.
- Stáhněte si knihovnu libxml2 ze stránek tvůrce (nebo přes balíčkovací systém v Linuxu) a pomocí Reader API zpracujte soubor users.xml. Načítání musí být robustní.
- Napište kód pro obecný AVL strom. Ověřte jeho správnou funkčnost.
- Napište kód pro spojový seznam a spolu s AVL stromem postavte databázi uživatelů.
- Pomocí XML Reader API načtěte vstupní soubor do databáze.
- Vytvořte interaktivní menu pro přidávání a mazání uživatelů a pro vyhledávání v databázi.
Odevzdání programu Základ a Náročnější
Řádně fungující program je nutné odevzdat do 7.2.2014, 23.59 SEČ. Jiný termín odevzdání ze závažných důvodů je nutné dopředu domluvit mailem. Pouze zdrojový kód (popř. i Makefile) výsledného programu odešlete na mou mailovou adresu.
Odevzdání programu Express
Řádně fungující program je nutné odevzdat do 3.11.2013, 23.59 SEČ. Jiný termín odevzdání ze závažných důvodů je nutné dopředu domluvit mailem. Pouze zdrojový kód (popř. i Makefile) výsledného programu odešlete na mou mailovou adresu.